Marco Cencini and Guy Aston
Resurrecting the
corp(us|se):
towards an encoding
standard for interpreting data
1. Why interpreting studies need an encoding
standard
Like all speech, interpreting dies on the air. In order to study it, we
need to resurrect the corpse by recording and transcribing it, thereby
transforming the corpse into a corpus.
Interpreted events seem particularly hard to
resurrect in this manner, however. In the first place, interpreting data is not
readily available. Interpreters are often reluctant to be recorded, and
many interpreting contexts make it difficult to obtain a single two-track
recording of the original and its interpretation, which is essential in order
to understand the relative timing involved. Since transcription is also time-
and skill-demanding, the quantity of data obtainable by the single researcher
is usually very limited. And since permission to use these data is typically
restricted to a particular project, it is rarely feasible to integrate them
with data collected in other projects. There is a clear need to make
interpreting data public, and to design corpora in such a way as to make these
data readily interchangeable.
Even if I have access to data collected by others, in
fact, these may be of little use to me directly. No transcription is a complete
record of a spoken event: you may be interested only in interpreters’ words, I
may be interested in their pauses and prosodies. Our transcriptions will
consequently differ. There is no way of guaranteeing that a transcription of
yours will capture all the features I am interested in, making it desirable
that not only transcriptions, but also the original recordings be made
available, so that I can revise your transcription and add to it to bring it
into line with my requirements. Even where we are interested in the same
things, we may not transcribe them in the same way: you may transcribe pauses
with a number indicating the pause length between brackets, while I may
transcribe them with plus signs, the number of such signs indicating the total
length of the pause. Effective interchangeability requires a basic set of
shared transcription conventions.
Even were other data to be available, however, and to
be transcribed using shared conventions, the problem would still remain of
accessing these data and of retrieving instances from them of the phenomena
with which we are concerned. The moment we are speaking of large quantities of
data, this problem becomes one of machine readability – of making data
storable, retrievable and analysable by computer. Nowadays virtually all
transcriptions of speech are typed into computers. However, this is usually
done in application-specific and platform-specific formats, which depend on the
use of a particular programme on a particular type of machine. Anyone who has
tried to take an MS-Word file and to convert it into WordPerfect, or to read it
on a Macintosh, will be only too aware of the problems: spacing and fonts may
change in unpredictable manners, and diacritics may become incomprehensible
symbols. There is no generally agreed manner of representing the information
implied by specific characters or formatting instructions which is application-
and platform-independent. Nor is there any agreed means of providing
metatextual information concerning the transcription itself – to indicate the
setting in which the interpreting event takes place and the participants, for
example – and concerning particular parts of that transcription – who is the
speaker of each utterance, paralinguistic features and non-verbal events,
overlaps and pauses, transcriber comments etc. – in an unambiguous and
application-neutral manner.
As far as concerns the problem of availability, one
promising source of data is TV interpreting. This is readily recordable, and
poses relatively few problems of permission. It also includes a wide range of
interpreting modes, from simultaneous to consecutive and chuchutage. Here we
will discuss some of the problems involved in transcribing and encoding TV
interpreting data in an interchangeable machine-readable format, illustrating
our proposals for a possible standard. The variety of interpreting to be found
on TV makes it a good field for the development and testing of these proposals,
which we believe should be fairly readily extendable to data from conference
and contact interpreting contexts.
As far as interchangeability is concerned, four main
problems emerge. We have already hinted at that of permission, and the need for
researchers to ensure that their data can be freely passed to others – a
problem which can only be solved by general consensus among researchers in the
field. The second concerns transcription, and the need to establish an agreed
set of minimal norms as to what to transcribe, and how to transcribe it. The
third concerns the availability of the original audio or video recording: only
if the original recording is made available, as well as the transcript, will it
be possible for another researcher to check and/or expand my transcription. The
fourth problem is that of encoding: how to make transcriptions
machine-readable, adopting application- and platform-independent standards for
representing textual and metatextual information. What particular researchers
will want to transcribe ultimately remains an individual choice: what is
important is that the ways in which they transcribe and encode their
transcriptions should follow standardised practices. This paper first examines
what we perceive as basic requirements in transcribing interpreting data, and
then proposes ways in which such transcriptions can be encoded in a standard
machine-readable format.
2. Some basic requirements for encoding TV interpreting data
While exactly what we transcribe will depend on what we are interested
in, in any transcription we are likely to want to include metatextual
information concerning the overall context
– the place and time, the
setting, the participants and the overall purpose and topic. In the case of TV
interpreting data, we are also likely to want to indicate the interpreting mode
(simultaneous, consecutive, chuchutage, etc.), the interpreter’s position
(on- or off-screen), and the primary function of the interpreting –
whether it serves to guarantee communication between the participants on
screen, or between these participants and the viewing audience. In the former
case, the interpreter functions as a buffer between the participants on
screen. In the latter, the interpreter functions as an amplifier of the
televised event in order to reach a wider audience.
Other types of metatextual
information relate not to the overall context, but to specific moments and
particular utterances. Any transcription of talk involving more than one
speaker will need to indicate the beginning, the end, and the speaker of each
utterance, and TV interpreting data poses particular problems in these
respects. In the first place, it is necessary to analyse the notion of speaker
in greater detail. Interpreters may speak either as the animators of talk
originally produced by other participants in another language (Goffman 1981),
or else as conversationalists in their own right, speaking not for others but
for themselves. This choice of participant status is typically reflected
in the reference of first person pronouns: where the interpreter’s utterance is
produced to animate another participant’s previous talk, I will
generally refer to that participant rather than to the interpreter. Speaking as
the animator of another’s talk implies that the interpreter’s utterance corresponds
to one or more utterances produced in a different language by another
participant, which it will normally parallel in content – of
which it constitutes, to use Wadensjo’s term (1998), a rendition.
Secondly, it is necessary to pay
particular attention to the timing of utterances: not just where they
start and end, but how they intertwine. Both simultaneous interpreting and
chuchutage are characterised by large proportions of overlapping speech. In
everyday two-party conversation, conversational participants observably orient
to overlaps on the floor of talk, for instance by treating the overlap as
co-producing the first speaker’s utterance, or alternatively as interruptively
signalling disagreement and predicting repetition and expansion once the first
utterance has finished (Zorzi, 1980). In interpreting contexts, however,
overlapping talk need not have these implications (Roy, 1996), since two
distinct floors of talk may be involved
– a first floor of communication
in the first language, and a second floor of communication in the second
language. Provided that they do not interfere acoustically, overlaps between
talk on different floors are not generally treated as significant: in
simultaneous or chuchutage mode, an interpreter may be able to talk in the L2
without being perceived as interrupting or contributing to the L1 talk which
s/he is interpreting. Where the interpreter functions as amplifier (in either
simultaneous or consecutive mode), s/he is in fact usually excluded from
participating in the first floor, while having a near-monopoly in the second.
Arguably, therefore, in transcribing TV interpreting data, we need to
distinguish utterances, and particularly overlaps, according to their floor
status (see 3.2 below for examples).
In the next section we suggest ways in which the
features outlined in this section can be encoded in an application- and
platform-independent machine-readable format.
3. Encoding with the TEI guidelines
The Text Encoding Initiative (TEI) is a major international project
aiming to establish application- and platform-independent norms for the
encoding of all types of electronic text (Burnard & Rahtz, forthcoming).
The TEI guidelines (Burnard & Sperberg-McQueen, 1993) describe the
principles employed and illustrate how a wide range of features and different
kinds of texts can be encoded. Originally designed to use the Standard General
Markup Language (SGML), TEI has since been adapted to render it compatible with
the Extendible Markup Language (XML), which is rapidly replacing HTML as the language
of the Internet. We take as our starting point the TEI guidelines for encoding
spoken texts in XML, elaborating these to take account of the particular
features of TV interpreting data outlined in the last section.[1]
3.1. From reader-friendly to machine-friendly encoding
Proposals for the transcription of recorded speech have generally
emphasised the need for the latter to be easily interpretable for the human
reader (Edwards 1993). For this reason, they have generally adopted many of the
conventions employed in the best-known type of language which is
written-to-be-spoken, the playscript. Example (1) shows what we believe to be a
typical transcription of this kind involving interpreting data:
(1) Greetings
A: Hi (...) how are [you?]
I: [Ciao]
come +stai?*
B: +Bene * (laughs)
e
tu?
I: Fine and you?
This
extract represents an invented example of the sort of recording which
researchers in interpretation have to transcribe, with two primary participants
(A and B) speaking two different languages and communicating via the
interpreter (I). It also illustrates some common practices followed to
transcribe conversational interaction: the transcriber has focussed on various
features of the original recording and chosen various graphical resources to
represent them. In this case, the identity of the speakers is signalled by the
initials in bold at the beginning of each utterance. Pauses are represented by
“(…)”, and non-verbal events by a description in parentheses. To cope with the
particular characteristics of interpreting, the transcription introduces
particular conventions to indicate the floor status of contributions: overlaps
due to the simultaneous interpretation of the interpreter on a different floor
are marked by square brackets (the words “you” and “ciao” in the first two
utterances), while the beginning and end of conversational overlaps occurring
on the same floor are marked by “+” and “*” (the words “stai” and “bene” in the
second and third utterances).
Example (1) is displayed in a reader-friendly
format, conceived taking into account the needs and skills of the human reader:[2] its form is designed in such a way as to help the reader understand its
content. Thus, for instance,
you can understand that “Greetings” is a title from the fact that it is centred
at the top of the text and is in italics; you can understand that a new
utterance begins from the fact that a new line starts with a letter followed by
a colon in bold. Similarly, the temporal alignment of overlapping utterances is
suggested by the spatial arrangement of the text on the page.
The problem is that once you have stored a transcription like this on a
computer, the machine will not understand it. Computers are very good at
remembering things, but not at interpreting
them: they are not able to infer information from documents in the way that
human readers can. A computer will not necessarily understand, for instance,
that the letters at the beginning of each utterance in (1) are not words uttered
by a speaker but codes identifying the speaker
– nor indeed that this is a
spoken text made of four utterances, that “Greetings” is a title, that
“(laughs)” is something that ‘happens’ and not something which is said, that
“you” and “ciao” occur at the same time, and so on. The main problem is that
there is no clear distinction between textual information (the actual words
spoken) and metatextual information (showing who says them, in what way and
when). If we want our transcription to be machine-friendly, so that a computer can understand the
information implicitly contained
in a document, we need to make this information explicit for the machine, distinguishing metatextual from
textual information and rendering both types non-ambiguous.
This is precisely what encoding is all about. It is based on the
principle of complete detachment of content
from form (Watson, 1999), and concerns the process by which we add
metatextual information to a text and keep this information separate from the
text, so as to increase the computational tractability of data. We now look at
how we can put this principle into practice following the TEI guidelines.
3.2. Elements and attributes
For
a start, we can tell the computer what our text is and what it is made of. To
do so, the TEI scheme proposes to mark up the text to indicate its elements. Elements are the “objects” documents are made of, or, to be
slightly more precise, the features we want to inform our computer about. In
(1), we might say that our document is a spoken text made up of four different
utterances, which contain words, pauses and non-verbal events. Translating into
TEI we have:
(2)[3] <text>
<u>hi <pause/>how
are [you?]</u>
<u>[ciao] come +stai?*</u>
<u>+bene* <vocal desc=“laughs”/> e tu?</u>
<u>fine and you?</u>
</text>
In (2), we have explicitly indicated four different kinds of elements:
<text>, <u>, <pause/> and <vocal/>. The labels
indicating these elements are distinguished from the words of the transcript
through the use of angle brackets: these delimit the markup tags, which are the features we
insert to name and identify features of a text. Where relevant, the tags mark
the “boundaries” of an element: we use a start tag (<element>) to mark the beginning of the
element, and an end tag
(</element>, with a slash following the opening angle bracket) to mark
its end. Everything occurring between the start- and end-tag is contained in that element. Thus
in (2), the text contains all the words and elements we find between
<text> and </text>, while each utterance contains all the words and
elements found between one <u> and the next </u>.
The remaining elements introduced, <pause/> and <vocal/>, do
not contain words or other elements, and are therefore empty elements. Empty elements
have a slightly different syntax in XML, since they do not have separate start
and end tags, but only a single tag with a slash before the closing angle
bracket (<element/>).[4]
To inform the computer about the producers of the various utterances in
(2) we can use element attributes.
Attributes are specifications we
attach to an element to add further information about it. To indicate the
identity of the speaker of each utterance, we use the attribute who, specifying the identity of the
speaker as the value of that attribute following the = sign. But we can
also add further attributes, as in (3):
(3) <text>
<u who=“A”
id=“u1” lang=“eng” corresp=“u2”>
hi
<pause/>how are [you?]
</u>
<u who=“I” id=“u2” lang=“ita” corresp=“u1”>
[ciao] come +stai?*
</u>
<u who=“B”
id=“u3” lang=“ita” corresp=“u4”>
+bene* <vocal
desc=“laughs”/>e tu?
</u>
<u who=“A”
id=“u4” lang=“eng” corresp=“u3”>
fine
and you?
</u>
</text>
Here
the other attributes specify the number of the utterance (the value of an
identifying attribute id), the
language in which the utterance is produced (the value of the attribute lang), and the correspondence between
the contents of different utterances – in (3), for instance, the attribute corresp is used to specify that the
element <u> identified as “u1” corresponds to that identified as “u2”,
and vice versa.
The encoding of overlap can be divided into two sub-problems: on the one
hand, we need to tell the computer which words are uttered at the same time,
and on the other, the floor status of the overlap involved. In (3), the first
utterance (by speaker A) overlaps with its simultaneous interpretation on a
separate floor by speaker I (the interpreter). To encode this information in
TEI, we propose the use of the element <anchor/>. An <anchor/> is
an empty element that can be used to identify any point in any text, and we use
it to identify any point where overlap starts or ends between talk on different
floors. Thus in (4) the starting points of the overlap, which were previously
identified by square left brackets in utterances “u1” and “u2”, have been
converted into <anchor/>s. Once we have identified the two beginnings, we
only have to express their simultaneity: this can be conveyed through the
attributes id and synch, whose values identify and express
the synchronisation of <anchor/> elements. The tags inserted in (4) mean
that the point “s1” identified by the <anchor/> in utterance “u1” is
synchronised with the point “s3” identified by the <anchor/> in utterance
“u2”.
(4) <text>
<u who=“A” id=“u1” lang=“eng” corresp=“u2”>
hi
<pause/>how are
<anchor id=“s1” synch=“s3”/>you?]
</u>
<u who=“I” id=“u2” lang=“ita” corresp=“u1”>
<anchor id=“s3” synch=“s1”/>ciao] come +stai?*
</u>
<u who=“B” id=“u3” lang=“ita” corresp=“u4”>
+bene* <vocal desc=“laughs”/>e tu?
</u>
<u who=“A” id=“u4” lang=“eng” corresp=“u3”>
fine
and you?
</u>
</text>
Repeating
the same process for the points at which the overlap ends we obtain:
(5) <text>
<u who=“A” id=“u1” lang=“eng” corresp=“u2”>
hi
<pause/>how are <anchor id=“s1” synch=“s3”/>
you?<anchor id=“s2” synch=“s4”/>
</u>
<u who=“I” id=“u2” lang=“ita” corresp=“u1”>
<anchor
id=“s3” synch=“s1”/>ciao
<anchor id=“s4” synch=“s2”/> come +stai?*
</u>
<u who=“B” id=“u3”
lang=“ita” corresp=“u4”>+bene* <vocal desc=“laughs”/>e tu?
</u>
<u who=“A” id=“u4” lang=“eng” corresp=“u3”>
fine
and you?
</u>
</text>
From
this markup we (and also our computer) can infer that utterances u1 and u2
overlap between the points indicated by the four synchronised <anchor/>s.[5]
As far as conversational overlaps are concerned (i.e. on the same floor:
cf. 2 above), we can apply a similar mechanism, but using a different element
so as to distinguish them from overlaps on different floors. The TEI element
<seg> can be used to identify any (arbitrary) portion of a text, whatever
its length, where the criterion used to segment the text is specified in the
attribute type. In our example, the
overlapped segments are the word “stai” in utterance “u2” and “bene” in
utterance “u3”. Thus we have:
(6) <text>
<u who=“A” id=“u1” lang=“eng” corresp=“u2”>
hi
<pause/> how are <anchor id=“s1” synch=“s3”/>
you?<anchor
id=“s2” synch=“s4”/>
</u>
<u who=“I” id=“u2” lang=“ita” corresp=“u1”>
<anchor
id=“s3” synch=“s1”/>ciao
<anchor
id=“s4” synch=“s2”/> come
<seg type=“overlap” id=“o1” synch=“o2”> stai?</seg>
</u>
<u who=“B” id=“u3” lang=“ita” corresp=“u4”>
<seg
type=“overlap” id=“o2” synch=“o1”> bene </seg>
<vocal desc=“laughs”/>e tu?</u>
<u who=“A” id=“u4” lang=“eng” corresp=“u3”>
fine and you?
</u>
</text>
3.3. The TEI header
Our
text is now marked up with tags specifying its structure; however, it still
lacks metatextual information about the setting of the interaction, for
instance, and the interpreting mode used. To add such information, which
concerns the entire text rather than a specific portion of it, the TEI scheme
uses the element <teiHeader>. This is placed at the beginning of the file
(as a preface to the text, as it were), and it can include general details
about the setting, the interpreting mode, the interpreter’s function and, more generally,
the source which the text was taken from, as well as the encoding and
transcription practices adopted. Notwithstanding appearances, this markup
procedure is relatively straightforward, and for reasons of space we shall not
go into it here, limiting ourselves to an example (for further details, see
Cencini, 2000).
(7)
<teiHeader>
<fileDesc>
<titleStmt>
<title>
L'ultimo valzer - an electronic
transcription</title>
<respStmt>
<resp>transcribed and encoded:</resp><name>Marco
Cencini</name>
</respStmt>
</titleStmt>
<extent>words:
526; kb: 10</extent>
<publicationStmt>
<authority>release
authority: SSLMIT</authority>
<availability
status="free">
<p>Available for purposes of
academic research and teaching only</p>
</availability>
</publicationStmt>
<sourceDesc>
<recordingStmt><recording>
<equipment><p>Recorded from TV to VCR</p></equipment>
<broadcast><bibl>
<title>An interview with Michael Bolton</title>
<author>RaiUno</author>
<respStmt>
<resp>interviewer</resp><name>Fabio Fazio</name>
<resp>interviewer</resp><name>Claudio
Baglioni</name>
<resp>interviewee</resp><name>Michael
Bolton</name>
<resp>Interpreter</resp><name>Unknown</name>
</respStmt>
<series><title>L'ultimo valzer</title></series>
<note>broadcast on <date>5 Nov.
1999</date></note>
</bibl></broadcast>
</recording></recordingStmt>
</sourceDesc>
</fileDesc>
<encodingDesc>
<classDecl><taxonomy>
<category
id="mod1"><catDesc>consecutive</catDesc></category>
<category
id="mod2"><catDesc>simultaneous</catDesc></category>
<category id="mod3"><catDesc>chuchotage</catDesc></category>
<category id="pos1"><catDesc>on-screen
interpreter</catDesc></category>
<category id="pos2"><catDesc>off-screen
interpreter</catDesc></category>
</taxonomy></classDecl>
</encodingDesc>
<profileDesc>
<creation><date>2
Jul 2000</date></creation>
<langUsage>
<language id="eng">english</language>
<language id="ita">italian</language>
</langUsage>
<particDesc>
<person
id="TICFF1" sex="m" role="interviewer">
<persName>Fabio
Fazio</persName>
<firstLang> Italian</firstLang>
</person>
<!--
here follow definitions of the other persons -->
</particDesc>
<settingDesc><setting>
<!--
here follows a prose description of the setting -->
</setting></settingDesc>
<textClass><catRef
target="mod2 pos2"/></textClass>
</profileDesc>
</teiHeader>
3.4. Displaying the encoded text using stylesheets
Once
a text is fully marked up, we have solved our problems regarding machine
readability and application- and platform-independence, through the detachment
of content from form. In the process, however, we have made the text much
harder to read for human beings. XML technology provides a solution to this
apparent dichotomy between machine-friendly
and reader-friendly formats through the use of stylesheets.
A stylesheet is a file which can be linked to one or more encoded
documents to specify how they should be visualised and/or printed: it can thus
be used to display TEI markup in a more reader-friendly manner. Currently,
there are two different languages available for stylesheets: the Cascading
Style Sheet language (CSS), which provides for basic formatting options,
and the eXtensible Stylesheet Language (XSL), which provides for more
advanced formatting. Figure 1 shows an example of output from a CSS stylesheet.
It is a screen-shot taken from XMetaL,[6] a programme designed to write, edit and display XML- (and TEI-)
conformant files.

Figure 1. Visualisation
using a CSS stylesheet (XMetaL)
The stylesheet can be edited to choose what elements and attributes are
to be displayed and how. Here the value of the attribute who is shown at the beginning of each <u>, and empty elements
are indicated by diamonds. In addition the element <pause/> is displayed
as “(…)”, and the presence of <anchor/>s is marked by “+”. The struck-out
utterance at the beginning illustrates a more sophisticated formatting option:
it marks a <u> element produced by one of the primary participants which
lacks a correspondent in the production of the interpreter (a zero-rendition:
Wadensjo, 1998).
Figure 2 instead shows an example using an XSL stylesheet.[7] Part of the text shown in figure 1 is here visualised as a musical
stave, and the temporal alignment of utterances is shown graphically:

Figure 2. Visualisation
in stave format using an XSL stylesheet
The advantages of using stylesheets to define the display of documents
are clear:
·
stylesheets can be used to display markup using
conventions with which readers are familiar;
·
the appearance of a transcript can be changed
by simply editing the stylesheet linked to it. This is particularly useful when
dealing with large corpora, since it guarantees complete consistency in the
representation of features in all the transcriptions by editing just one file
(the stylesheet);
·
there is no need to worry about the final
visual representation during transcription, nor to manually edit the transcript
subsequently: the computer automatically produces the display as specified in
the stylesheet;
·
the appearance of the transcript can be adapted
to the medium in which it is to be read. For instance, if transcripts are to be
consulted as web pages, different colours can be used to highlight particular
features, while if printouts are required, a stylesheet using different fonts
and spacing can be used.
4. From looking at to looking for
Markup
is not only useful to obtain pretty outputs from stylesheets in order to look at your data, but also to look for specific features in your data. SARA
(SGML-Aware Retrieval Application) is a programme originally developed for use
with the British National Corpus (BNC), a 100-million-word corpus of spoken and
written British English which is largely TEI-conformant, shortly to be released
in an XML-compatible version. Figure 3 is a SARA screen-shot showing a
concordance of the word “bene” in the Television Interpreting Corpus (TIC), a
TEI-conformant pilot corpus of TV interpreting transcriptions (Cencini, 2000).
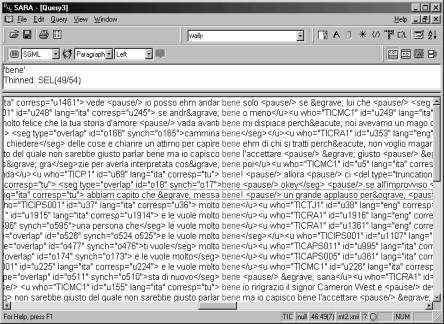
Figure 3. Bene in the TIC: KWIC
concordance display showing XML mark up.
In figure 3, all the XML tags are shown, but SARA also allows you to
convert these tags into more reader-friendly outputs, as in figure 4:
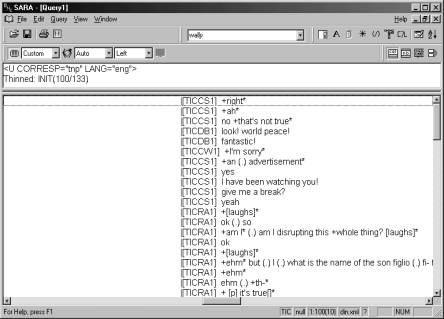
Figure 4. Utterances in
English without corresponding interpreter utterances in Italian in the TIC:
KWIC concordance display, mark up automatically converted to reader-friendly
format.
Here values of who attributes on utterances are displayed in
square brackets, pauses as “(.)”, overlaps on different floors (<anchor/>
elements) as “[^]”, and conversational overlaps between “+” and “*”.
The concordance in figure 4 also provides an
example of the more sophisticated searches that can be performed with this
software. It lists all the English utterances produced by one of the primary
participants which do not have a correspondent in the interpreter’s production
(i.e. with zero-renditions: Wadensjo, 1998). This search is possible because
SARA is able to exploit TEI markup to recognise (a) English utterances as
opposed to Italian ones; (b) interpreters’ utterances as opposed to those of
primary participants, and (c) utterances with corresponding utterances as
opposed to ones without. The amount of context shown can be increased as
required: SARA also allows you to view the full text corresponding to a
particular concordance line, as in figure 5:
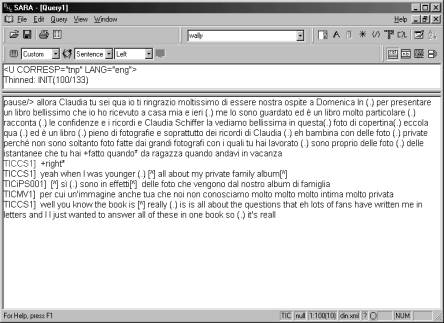
Figure 5. Full context of first line in figure 4: reader-friendly format (see note
3 above). TICCS1 = Claudia Schiffer; TICMV1 = Mara Venier; TICIPS001 =
Anonymous interpreter.
5. Conclusions
In
this short paper, we in no way pretend to have provided an exhaustive account
of issues in the encoding of interpreting data using the TEI guidelines. What
we hope to have done is to illustrate the potential of the latter, in the
belief that TV interpreting provides a varied and challenging context for
experimentation, from which the principles outlined here can be extended with
relative ease to conference and contact interpreting contexts. TEI has met with
rapid and widespread acceptance in many academic communities, particular as far
as textual corpora are concerned, and our work so far suggests that it can
provide a valid tool for the encoding of all types of interpreting data in an
interchangeable format.
In this respect, we would stress the flexibility and
extendability of TEI to cover features of interpreting data not discussed here
but of potential interest to many researchers – pause length, prosody, voice
quality, kinesics, décalage, etc. – not to mention the coding of different
kinds and degrees of correspondence between utterances, shifts in footing and
language within utterances, etc. Of particular value for researchers in
interpreting is the fact that TEI also permits the alignment of different files
containing parallel data, and hence the alignment of different interpretations
of the same source text, or the alignment of the transcription with digitised
audio or video. Work on parallel corpora in the area of translation studies
makes it likely that over the next few years, XML-aware parallel concordancing
software will be developed which will allow the retrieval of corresponding
utterances or segments across different files, so that we will not only be able
to search our corpus for occurrences of bene, but also for the
corresponding translations and audio/video, and to view and hear those
interpreter utterances which correspond to source language utterances which
contain bene.
Maximising the benefit to interpreting studies of such
technical developments will however depend on significant quantities of data
being available to the research community in standardised formats. As Sergio
Straniero (1999: 323) puts it:
It is only through the empirical observation of
regularities of situation and behaviour that it is is possible to create
corpora which, in turn, enable the determination of norms [...], a major lacuna
in the field of interpreting.
The development of widely acceptable encoding conventions would seem an
essential prerequisite to the construction and comparison of the corpora
necessary to determine such interpreting norms.
References
Burnard, L. & C. Sperberg-McQueen eds. (1994). Guidelines
for electronic text encoding and interchange (P3). Chicago and
Oxford: ACH-ACL-ALLC.
Burnard, L. & S. Rahtz (forthcoming). An
introduction to TEI (provisional title). Utrecht: Kluwer.
Cencini, M. (2000). Il Television Interpreting
Corpus (TIC). Proposta di codifica
conforme alle norme TEI per trascrizioni di eventi di interpretazione in
televisione. Unpublished dissertation. Forlì: SSLMIT.
Dodd, A. (2000). SARA ver 0.941. Oxford:
Oxford University Computing Services.
Edwards, J.A. (1993). “Principles and contrastive
systems of discourse transcription”. In J.A. Edwards & M.D. Lampert eds.
(1993). Talking data: transcription and
coding in discourse research. Hillsdale NJ: Erlbaum. 3-31.
Edwards, J.A. (1995). “Principles and alternative
systems in the transcription, coding and mark-up of spoken discourse”. In G.
Leech, G. Myers & J. Thomas eds. (1995). Spoken English on computer. Transcription, mark-up and application. London:
Longman. 19-34.
Goffman, E. (1981). Forms
of talk. Oxford: Blackwell.
Roy, C.B. (1996). “An interactional
sociolinguistic analysis of turn-taking in an interpreted event”. Interpreting,
1. 39-67.
Straniero
Sergio, F. (1999). “The interpreter on the (talk) show:
interaction and participation frameworks”. The translator, 5. 303-326.
Wadensjö, C. (1998). Interpreting as
interaction. London: Longman.
Watson, D.G. (1999). Brief history of document markup. Online:
http://edis.ifas.ufl.edu/body_ae038
XMetaL
ver. 2.0. (2000).
Toronto: Softquad software.
Zorzi, D. (1980). Parlare insieme: la co-produzione dell’ordine
conversazionale. Bologna: Cooperativa Libraria Universitaria Editrice.